17106050008- Indri Dwi Juanti
Algoritma K-Means merupakan algoritma klasterisasi yang mengelompokkan data berdasarkan titik pusat klaster (centroid)
terdekat dengan data. Tujuan dari K-Means adalah pengelompokkan data dengan memaksimalkan kemiripan data dalam satu klaster dan meminimalkan kemiripan data antar klaster. Ukuran kemiripan yang digunakan dalam klaster adalah fungsi jarak . Perhitungan Jarak antara data dan centroid menggunakan rumus diantaranya adalah Manhattan/City Block Distance, Euclidean Distance dan Minkowski Distance.
Karakteristik K-Means
- K-Means sangat cepat dalam proses clustering
- K-Means sangat sensitif pada pembangkitan centroid awal secara random
- Memungkinkan suatu cluster tidak mempunyai anggota
- Hasil clustering dengan K-Means bersifat tidak unik (selalu berubah-ubah) – terkadang baik, terkadang jelek
- K-means sangat sulit untuk mencapai global optimum
K-Means Clustering ini secara umum dilakukan dengan algoritma dasar sebagai berikut:
- Tentukan jumlah cluster
- Alokasikan data ke dalam cluster secara random
- Hitung centroid/rata-rata dari data yang ada di masing-masing cluster
- Alokasikan masing-masing data ke centroid/rata-rata terdekat
- Kembali ke Step 3, apabila masih ada data yang berpindah cluster atau apabila perubahan nilai centroid, ada yang di atas nilai threshold yang ditentukan atau apabila perubahan nilai pada objective function yang digunakan di atas nilai threshold yang ditentukan
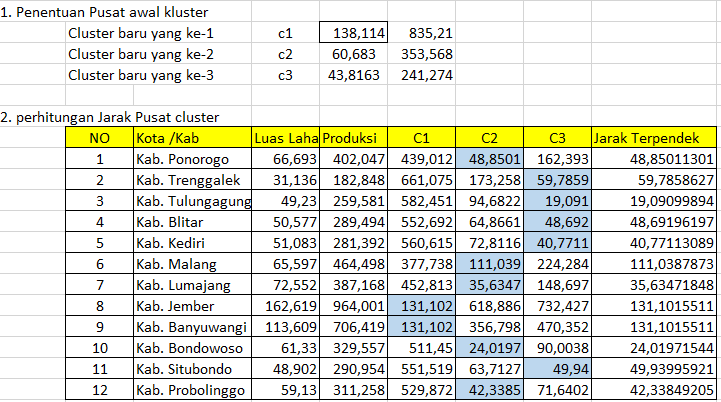
Contoh Perhitungan K-Means :
Diketahui : jumlah cluster = 3, jumlah data = 12 , dan jumlah atribut =2


2. Perhitungan jarak pusat cluster dengan menggunakan rumus Euclidian distance



3. Pengelompokkan Data
Dari data diatas kemudian data dikelompokkan , berdasarkan jarak hasil perhitungan kemudian dilakukan perbandingan dan dipilih jarak yang terdekat antara data dan pusat cluster.

tanda * pada tabel diatas merupakan jarak terpendek pada Cn .
4. Menentukan Pusat Cluster Baru
Setelah diketahui anggota pada masing-masing cluster , kemudian pusat cluster baru dihitung berdasarkan data anggota di tiap-tiap cluster . sesuai dengan rumus pusat anggota cluster . Cara menghitungnya yaitu dengan menjumlahkan seluruh anggota masing-masing cluster dibagi jumlah anggotannya .

lakukan perhitungan yang sama untuk iterasi ke 2

untuk mencari iterasi ke 3 , lakukan langkah yang sama seperti yang telah dilakukan sebelumnya . sehingga diperoleh hasil sebagai berikut :
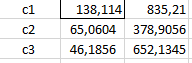


Iterasi akan berakhir jika titik pusat dari setiap cluster tidak berubah
lagi dan tidak ada lagi data yang berpindah dari
satu cluster ke cluster yang lain.
Untuk Perhitungan Lengkapnya dapat dilihat melalui link berikut :
https://drive.google.com/file/d/1118CfrONmu-JQBjBPxNm_TTYsJZh5fQp/view?usp=sharing
sumber : http://journal.umy.ac.id/index.php/st/article/download/708/858
https://informatikalogi.com/algoritma-k-means-clustering/
https://syafrudinmtop.blogspot.com/2015/10/contoh-perhitungan-manual-kmeans-klastering.html

2 replies on “K Means”
[…] response data,” n.d.). Salah satu algoritma yang digunakan metode unsupervised learning adalah K-Means […]
LikeLike
[…] atau Partitioning Around Medoids (PAM) adalah algoritma clustering yang mirip dengan K-Means. Perbedaan dari kedua algoritma ini yaitu algoritma K-Medoidsatau PAM menggunakan objek sebagai […]
LikeLike