Categories
Categories
Aggregation

Pengertian
Agregasi atau aggregation adalah sebuah transformasi data didalam data mining Ayang merupakan operasi summary (peringkasan) diaplikasikan pada data numerik.
Dalam istilah yang lebih sederhana, ini mengacu pada menggabungkan dua atau lebih atribut (atau objek) menjadi atribut tunggal (atau objek).
Tujuan
→ Pengurangan Data
Mengurangi jumlah objek atau atribut. Untuk menghasilkan set data yang lebih kecil dan karenanya membutuhkan lebih sedikit memori dan waktu pemrosesan, dan karenanya, agregasi dapat memungkinkan penggunaan algoritma penambangan data yang lebih mahal.
→ Perubahan Skala
Dapat bekerja sebagai perubahan ruang lingkup atau skala dengan memberikan tampilan data tingkat tinggi alih-alih tampilan tingkat rendah.
Misalnya pada data penjualan harian digabungkan untuk menghitung pendapatan perbulan dan pertahun dengan dirata-rata atau ditotal. Langkah ini dilakukan dengan memanfaatkan operator data cube (operasi roll up/meringkas).
Contoh lain:
- Kota-kota dikumpulkan menjadi daerah, negara bagian, negara, dll.
- Hari digabungkan menjadi beberapa minggu, bulan, dan tahun.
→ Lebih Banyak Data “Stabil”
Data Teragregasi cenderung memiliki variabilitas yang lebih sedikit.
Terkait
Artikel terkait transformasi data Agregasi yaitu tentang Data Cube Agreggation dapat disimak di tautan berikut.
https://towardsdatascience.com/data-mining-101-dimensionality-and-data-reduction-2a8fa427b092
Mind Map : Data Mining – Preprocessing – Data Transformation – Aggregation
Source:
https://towardsdatascience.com/data-preprocessing-in-data-mining-machine-learning-79a9662e2eb
http://chandraallim.blogspot.com/2018/01/transformasi-data-dalam-tahapan-data.html
by 1710605007 – Andika Rizki Syahputra
Categories
C.4.5
C.4.5 merupakan kelompok algoritma Decision Tree. Algoritma ini mempunyai input berupa training samples dan samples. Training samples berupa data dan contoh yang akan digunakan untuk membangun sebuah tree yang telah diuji kebenarannya. Sedangkan samples merupakan field-field data yang nantinya akan digunakan sebagai parameter dalam melakukan klasifikasi data. Algoritma C.4.5 dibuat oleh Ross Quinlan yang merupakan pengembangan dari ID3 yang juga dibuat oleh Quinlan.
sumber : https://www.labwisnu.com/2018/06/pengertian-algoritma-c45.html
Categories
Normalisasi
Normalisasi pada Data Mining adalah proses penskalaan nilai atribut dari data sehingga bisa jatuh pada range tertentu. Hal ini berguna ketika data berada pada range berbeda dan sulit melihat apakah data tersebut memiliki kontribusi penting ketika proses learning selanjutnya.
sumber : https://opensourcefaisal.blogspot.com/2016/04/normalisasi-pada-data-mining.html
Categories
ID3
Iterative Dichotomiser 3 (ID3) adalah algoritma decision tree learning
(algoritma pembelajaran pohon keputusan) yang paling dasar. Algoritma ini melakukan pencarian secara menyeluruh (greedy) pada semua kemungkinan pohon keputusan.
Salah satu algoritma induksi pohon keputusan yaitu ID3 (Iterative Dichotomiser 3). ID3 dikembangkan oleh J. Ross Quinlan. Algoritma ID3 dapat diimplementasikan menggunakan fungsi rekursif (fungsi yang memanggil dirinya sendiri). Algoritma ID3 berusaha membangun decision tree (pohon keputusan) secara top-down (dari atas ke bawah) (David, 2004).
Contoh Soal : Kita menggunakan data 10 di bawah ini untuk membentuk suatu pohon keputusan sehingga apabila data baru dapat kita uji menggunkan poho keputusan di bawah ini :
Asal Sekolah (SMA/MA/SMK) NEM(Bahasa, Matematika, B Ing SMA) IPK (Informatika)
| NIM | AsalSekolah | Bhs | Mtk | BIng | IPK |
| 1 | MA | Istimewa9 | Sangat Baik( 7,3) | Baik (5,2) | 3,8 |
| 2 | SMA | Baik5 | Cukup (3,1) | Kurang (0,8) | 3,4 |
| 3 | SMK | cukup | Kurang (1,7) | Cukup (3,1) | 2,5 |
| 4 | MA | Baik | Baik (4,3) | Cukup (3,5) | 3,3 |
| 5 | SMA | cukup | Baik (5,2) | Sangatbaik (6,2) | 3,6 |
| 6 | SMK | kurang | Cukup (2,8) | Kurang (1,1) | 1,9 |
| 7 | SMA | baik | Istimewa (9,3) | Sangatbaik (7,5) | 3,2 |
| 8 | SMK | baik | Cukup (2,5) | Baik (4,6) | 2,6 |
| 9 | MA | cukup | Baik (4,4) | Cukup (2,3) | 2,8 |
| 10 | SMA | baik | Sangatbaik (6,8) | Baik (4,3) | 3,3 |
Keterangan:
Istimewa : 8-10
sangat baik : 6-8
baik : 4-6
cukup :2-4
kurang : 0-2
Memuaskan : 3-4
Mengecewakan: 0
Jawab:
| NIM | AsalSekolah | Bhs | Mtk | BIng | IPK | Kategori | ||
| 1 | MA | Istimewa | Sangat Baik | Baik | 3,8 | Memuaskan | ||
| 2 | SMA | Baik | Cukup | Kurang | 3,4 | Memuaskan | ||
| 3 | SMK | cukup | Kurang | Cukup | 2,5 | Mengecewakan | ||
| 4 | MA | Baik | Baik | Cukup | 3,3 | Memuaskan | ||
| 5 | SMA | cukup | Baik | Sangatbaik | 3,6 | Memuaskan | ||
| 6 | SMK | kurang | Cukup | Kurang | 1,9 | Mengecewakan | ||
| 7 | SMA | baik | Istimewa | Sangatbaik | 3,2 | Memuaskan | ||
| 8 | SMK | baik | Cukup | Baik | 2,6 | Mengecewakan | ||
| 9 | MA | cukup | Baik | Cukup | 2,8 | Mengecewakan | ||
| 10 | SMA | baik | Sangat Baik | Baik | 3,3 | Memuaskan | ||
| Memuaskan | 6 | |||||||
| Mengecewakan | 4 | |||||||
| Total | 10 | |||||||
Rumus Entropi
Mencari Entropi total :
Entopi
Entopi 0,970950594
Hitung entropi tiap nilai-nilainya kemudian hitung gain per atributnya dengan rumus=

Sehingga didapatkan hasil:
| node | atribut | nilai | frekuensi | Frek. sum | Frek. (puas) | Frek. (kecewa) | entropi | gain |
| 1 | Asal Sekolah | MA | 3 | 10 | 2 | 1 | 0,918295834 | 0,695461844 |
| SMA | 4 | 4 | 0 | 0 | ||||
| SMK | 3 | 0 | 3 | 0 | ||||
| Bhs | Istimewa | 1 | 10 | 1 | 0 | 0 | 0,334497797 | |
| Baik | 5 | 4 | 1 | 0,721928095 | ||||
| cukup | 3 | 1 | 2 | 0,918295834 | ||||
| kurang | 1 | 0 | 1 | 0 | ||||
| Mtk | Istimewa | 1 | 10 | 1 | 0 | 0 | 0,419973094 | |
| Sangat Baik | 2 | 2 | 0 | 0 | ||||
| Baik | 3 | 2 | 1 | 0,918295834 | ||||
| Cukup | 3 | 1 | 2 | 0,918295834 | ||||
| Kurang | 1 | 0 | 1 | 0 | ||||
| Bing | Sangatbaik | 2 | 10 | 2 | 0 | 0 | 0,219973094 | |
| Baik | 3 | 2 | 1 | 0,918295834 | ||||
| Cukup | 3 | 1 | 2 | 0,918295834 | ||||
| Kurang | 2 | 1 | 1 | 1 |
Karena nilai gain terbesar adalah Gain (Asal Sekolah), maka atribut “Asal Sekolah” menjadi node akar (root node).
Kemudian pada “Asal Sekolah” MA, memiliki 3 kasus dan frekuensi kedua kategori (puas dan kecewa) tidak bernilai 0. Dengan demikian “Asal Sekolah” MA menjadi node.
Sedangkan pada “Asal Sekolah” SMA dan SMK keduanya memiliki nilai 0 pada salah satu frekuensi kategori (puas dan kecewa). Dengan demikian “Asal Sekolah” SMA dan SMK menjadi daun atau leaf.
Sehingga pohon keputusan node 1 menjadi:

Kemudian dilanjutkan dengan perhitungan pada node 1.1
Pilih nilai atribut yang berasal dari “Asal Sekolah” MA. Setelah didapatkan kemudian menghitung kembali entropi tiap nilai atribut tersebut.
Kemudian menghitung kembali Gain tiap atribut dengan menggunakan entropi “Asal Sekolah” yaitu : 0,695461844
Sehingga didapatkan hasil:
| node | atribut | nilai | frekuensi | frek sum | Frek. (puas) | Frek. (kecewa) | entropi | gain |
| 1.1 | Bhs | Istimewa | 1 | 3 | 1 | 0 | 0 | 0,918295834 |
| Baik | 1 | 1 | 0 | 0 | ||||
| cukup | 1 | 0 | 1 | 0 | ||||
| Mtk | Sangat Baik | 1 | 3 | 1 | 0 | 0 | 0,251629167 | |
| Baik | 2 | 1 | 1 | 1 | ||||
| Bing | Baik | 1 | 3 | 1 | 0 | 0 | 0,251629167 | |
| Cukup | 2 | 1 | 1 | 1 |
Dari data diatas di dapatkan gain terbesar yaitu Bhs. Sehingga atribut “Bhs” menjadi node 1.1
Kemudian pada atribut “Bhs” memiliki 3 nilai yaitu Istimewa, baik, dan Cukup. Dimana ketiganya memiliki nilai 0 pada salah satu frekuensi kategori (puas dan kecewa). Dengan demikian “Bhs” Istimewa, Baik, dan Cukup menjadi daun atau leaf semua.
Sehingga hasil hasil akhir pohon keputusan menjadi:

DATA UJI
Misal di sajikan data berikut:
Kita mempunyai 10 data baru yang dapat kita gunakan sebagai data uji
| NIM | Nama | Asal Sekolah | Bhs | Mtk | B.ing | IPK |
| 1 | Lila | MA | 9 | 8 | 8 | 3,3 |
| 2 | April | MA | 9 | 5 | 7 | 2,8 |
| 3 | Seto | SMA | 6 | 8 | 7.5 | 2,8 |
| 4 | Cucum | MA | 5 | 9 | 8 | 2,9 |
| 5 | Indri | SMA | 4 | 7.25 | 8 | 2,4 |
| 6 | Hanif | SMA | 8.6 | 9 | 9 | 3,6 |
| 7 | Aziz | SMA | 9 | 7.25 | 6 | 3,0 |
| 8 | Ilham | MA | 8.4 | 9 | 7 | 3,2 |
| 9 | Iqbal | SMA | 4 | 9 | 8.6 | 2,6 |
| 10 | Alvin | SMK | 4 | 6 | 8 | 2,4 |
Langkah pertama beri keterangan kategori berdasarkan ketentuan awal, sehingga menjadi:
| NIM | Nama | Asal Sekolah | Bhs | Mtk | B.Ing | IPK | Kategori | |||
| 1 | Lila | MA | 9 | Istimewa | 8 | Sangat Baik | 8 | Sangat Baik | 3,3 | Memuaskan |
| 2 | April | MA | 9 | Istimewa | 5 | Baik | 7 | Sangat Baik | 2,8 | Mengecewakan |
| 3 | Seto | SMA | 6 | Baik | 8 | Sangat Baik | 7.5 | Istimewa | 2,8 | Mengecewakan |
| 4 | Cucum | MA | 5 | Baik | 9 | Istimewa | 8 | Sangat Baik | 2,9 | Mengecewakan |
| 5 | Indri | SMA | 4 | Cukup | 7.25 | Istimewa | 8 | Sangat Baik | 2,4 | Mengecewakan |
| 6 | Hanif | SMA | 8.6 | Istimewa | 9 | Istimewa | 9 | Istimewa | 3,6 | Memuaskan |
| 7 | Aziz | SMA | 9 | Istimewa | 7.25 | Istimewa | 6 | Baik | 3,0 | Mengecewakan |
| 8 | Ilham | MA | 8.4 | Istimewa | 9 | Istimewa | 7 | Sangat Baik | 3,2 | Memuaskan |
| 9 | Iqbal | SMA | 4 | Cukup | 9 | Istimewa | 8.6 | Istimewa | 2,6 | Mengecewakan |
| 10 | Alvin | SMK | 4 | Cukup | 6 | Baik | 8 | Sangat Baik | 2,4 | Mengecewakan |
Kemudian cek apakah data sudah akurat sesuai dengan pohon tree di atas, hasilnya adalah :
| NIM | Nama | Asal Sekolah | Bhs | Mtk | B.Ing | IPK | Kategori | Hasil | |||
| 1 | Lila | MA | 9 | Istimewa | 8 | Sangat Baik | 8 | Sangat Baik | 3,3 | Memuaskan | Akurat |
| 2 | April | MA | 9 | Istimewa | 5 | Baik | 7 | Sangat Baik | 2,8 | Mengecewakan | tidak akurat |
| 3 | Seto | SMA | 6 | Baik | 8 | Sangat Baik | 7.5 | Istimewa | 2,8 | Mengecewakan | tidak akurat |
| 4 | Cucum | MA | 5 | Baik | 9 | Istimewa | 8 | Sangat Baik | 2,9 | Mengecewakan | tidak akurat |
| 5 | Indri | SMA | 4 | Cukup | 7.25 | Istimewa | 8 | Sangat Baik | 2,4 | Mengecewakan | tidak akurat |
| 6 | Hanif | SMA | 8.6 | Istimewa | 9 | Istimewa | 9 | Istimewa | 3,6 | Memuaskan | akurat |
| 7 | Aziz | SMA | 9 | Istimewa | 7.25 | Istimewa | 6 | Baik | 3,0 | Mengecewakan | tidak akurat |
| 8 | Ilham | MA | 8.4 | Istimewa | 9 | Istimewa | 7 | Sangat Baik | 3,2 | Memuaskan | Akurat |
| 9 | Iqbal | SMA | 4 | Cukup | 9 | Istimewa | 8.6 | Istimewa | 2,6 | Mengecewakan | tidak akurat |
| 10 | Alvin | SMK | 4 | Cukup | 6 | Baik | 8 | Sangat Baik | 2,4 | Mengecewakan | Akurat |
Sumber :
Click to access 100742-ID-algoritma-iterative-dichotomiser-3-id3-u.pdf
Categories
DBScan
Nadhij Hakiman Alim – 17106050026
Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
merupakan metode clustering yang digunakkan pada proses machine learning untuk memisahkan antara cluster dengan kepadatan tinggi dari cluster kepadatan rendah.
Berdasarkan seperangkat titik (mari kita berpikir dalam ruang bidimensional), DBSCAN mengelompokkan titik-titik yang berdekatan satu sama lain berdasarkan pengukuran jarak (biasanya jarak Euclidean) dan jumlah titik minimum. Hal ini juga menandai titik-titik yang berada di daerah dengan kepadatan rendah.
Concept Map : Data Mining – Discovery – Unsupervised – Klasterisasi – DBSCAN
Ref:
– https://medium.com/@elutins/dbscan-what-is-it-when-to-use-it-how-to-use-it-8bd506293818
– https://towardsdatascience.com/how-dbscan-works-and-why-should-i-use-it-443b4a191c80
Categories
FP Growth
Nadhij Hakiman Alim – 17106050026
Frequent Growth Algorithm, merupakan peningkatan pada metode Apriori. Algoritma ditujukan untuk menemukan pola, asosiasi, atau struktur sebab akibat dari kumpulan data dalam berbagai jenis database atau repositori data. Algoritma FP Growth mewakili database dalam bentuk pohon yang disebut Frequent Pattern Tree.
Struktur pohon ini akan menjaga hubungan antara itemset. Database dipecah menggunakan satu item yang berulang. Bagian yang terfragmentasi ini disebut “pattern fragment”. Butir pola yang terfragmentasi ini dianalisis. Maka dengan metode ini, waktu pencarian item yang berulang berkurang secara drastis.
Frequent Pattern Tree
FP-Tree adalah struktur mirip pohon yang dibuat dengan itemset awal dari database. Tujuan dari FP-Tree adalah untuk menambang pola yang paling sering berulang. Setiap node dari pohon FP mewakili item dari itemset.
Root node mewakili null sedangkan node yang lebih rendah mewakili itemset. Hubungan node dengan node yang lebih rendah (itemset dengan itemset lainnya) dipertahankan saat membentuk pohon.
Concept Map : Data Mining – Discovery – Unsupervised – Association – Apriori – FP Growth
Ref : https://www.softwaretestinghelp.com/fp-growth-algorithm-data-mining/
Categories
Logistic Regression
Pengertian
Adalah salah satu algoritma dasar dan populer untuk menyelesaikan masalah klasifikasi yang masuk dalam algrotima regresi non-linear. Dinamai sebagai ‘Regresi Logistik’, karena teknik dasarnya cukup mirip dengan Regresi Linier karena masih satu induk yaitu regresi.

Algoritma Logistic Regression digunakan untuk masalah klasifikasi, yang berupa analisis prediktif dan didasarkan pada konsep probabilitas.
Tujuan
Tujuan dari regresi logistik adalah untuk memperkirakan probabilitas sebuah peristiwa dengan variabel terikat yang berskala dikotomi.

Skala dikotomi yang dimaksud adalah skala data nominal dengan dua kategori, misalnya: Ya dan Tidak, Baik dan Buruk atau Tinggi dan Rendah.
Sebagai contoh,
- Untuk memprediksi apakah email itu spam (1) atau (0)
- Apakah tumornya ganas (1) atau tidak (0)
Jenis dari Logistic Regression
1. Regresi Logistik Biner
Tanggapan kategoris hanya memiliki dua 2 hasil yang mungkin. Contoh: Spam atau Tidak
2. Regresi Logistik Multinomial
Tiga atau lebih kategori tanpa memesan. Contoh: Memprediksi makanan mana yang lebih disukai (Veg, Non-Veg, Vegan)
3. Regresi Logistik Ordinal
Tiga atau lebih kategori dengan pemesanan. Contoh: Nilai film dari 1 hingga 5
Fungsi di dalam Logistic Regression
Fungsi Sigmoid
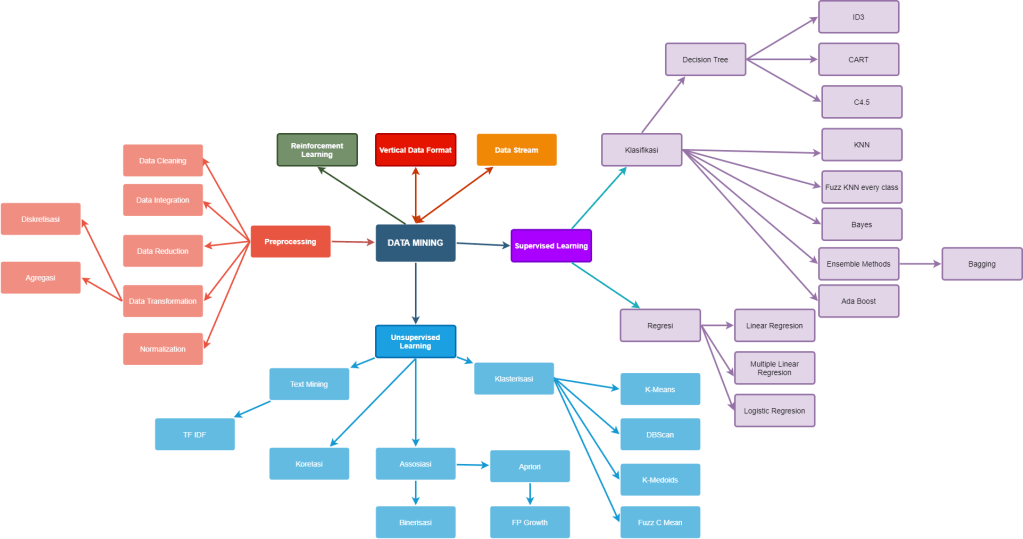
Untuk memetakan nilai prediksi ke probabilitas, kami menggunakan fungsi Sigmoid. Fungsi memetakan setiap nilai nyata menjadi nilai lain antara 0 dan 1. Dalam pembelajaran mesin, kami menggunakan sigmoid untuk memetakan prediksi ke probabilitas.

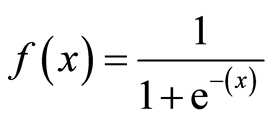
Representasi Hipotesis
Untuk regresi logistik memodifikasi sedikit dari rumus hipotesis linear regression

Fungsi Biaya
Dalam Linear Regression , fungsi biaya mewakili tujuan optimasi yaitu membuat fungsi biaya dan menguranginya sehingga dapat mengembangkan model yang akurat dengan kesalahan minimum.
Untuk regresi logistik, fungsi Biaya didefinisikan sebagai berikut.
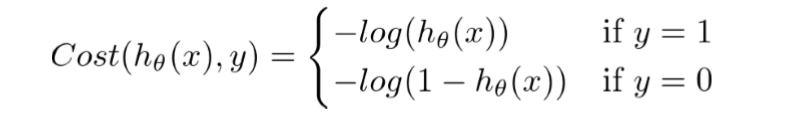
Dua fungsi di atas dapat dikompresi menjadi fungsi tunggal yaitu
Mind Map : Data Mining – Supervised Learning – Regresi – Logistic Regression
Source:
https://towardsdatascience.com/understanding-logistic-regression-9b02c2aec102
https://towardsdatascience.com/logistic-regression-detailed-overview-46c4da4303bc
https://searchbusinessanalytics.techtarget.com/definition/logistic-regression
by 17106050027 – Andika Rizki Syahputra
Categories
Unsupervised Learning
17106050001 – Aprilia Nuryanti
Unsupervised learning adalah salah satu tipe algoritma machine learning yang digunakan untuk menarik kesimpulan dari datasets yang terdiri dari input data labeled response. Metode unsupervised learning yang paling umum adalah analisa cluster, yang digunakan pada analisa data untuk mencari pola-pola tersembunyi atau pengelompokan dalam data. Salah satu algoritma yang digunakan metode unsupervised learning adalah K-Means algoritma.
Pendekatan unsupervised learning tidak menggunakan data latih atau data training untuk melakukan prediksi maupun klasifikasi. perbedaan Supervised Learning dengan Unsupervised Learning yaitu Supervised learning membutuhkan data training (harus dilatih terlebih dahulu) sedangkan unsupervised learning tidak membutuhkan data training (tidak perlu dilatih terlebih dahulu).
Misal dalam kasus pembagian kelompok mahasiswa pada suatu kelas yang akan dikelompokkan menjadi beberapa orang ini kedalam beberapa kelompok. Misalkan jumlah kelompok ada 4. Maka mahasiswa dikelompokkan menurut kesamaan ciri-ciri (atribut): berdasarkan indeks prestasi, jarak tempat tinggal atau gabungan keduanya. Dalam dua dimensi sumbu x merepresentasikan indeks prestasi, sumbu y merepresentasikan jarak tempat tinggal.
Teknik unsupervised : mahasiswa sebagai objek dari tugas kita, bisa dikempokkan dalam 4 kelompok menurut kedekatan IP dan jarak tempat tinggal. Pengelompokan ini, diasumsikan dalam satu kelompok, anggota-anggotanya harus memunyai kemiripan yang tinggi dibanding anggota dari kelompok lain.
Teknik supervised : output dari unsupervised dipakai sebagai guru dalam proses training dengan menggunakan teknik pengenalan pola , Dan dalam pemisahkan data training dan data testing (pelatih) maka diperlukan fungsi pemisah.
Categories
kNN
17106050001 – Aprilia Nuryanti
k-nearest neighbor (kNN) termasuk kelompok instance-based learning. Algoritma ini juga merupakan salah satu teknik lazy learning. kNN dilakukan dengan mencari kelompok k objek dalam data training yang paling dekat (mirip) dengan objek pada data baru atau data testing. Contoh kasus, misal diinginkan untuk mencari solusi terhadap masalah seorang pasien baru dengan menggunakan solusi dari pasien lama. Untuk mencari solusi dari pasien baru tersebut digunakan kedekatan dengan kasus pasien lama, solusi dari kasus lama yang memiliki kedekatan dengan kasus baru digunakan sebagai solusinya.
Pada Algoritma kNN terdapat beberapa metode perhitungan seperti Euclidean Distance dan Manhattan. untuk bisa memahami kedua metode perhitungan tersebut, maka perhatikan contoh berikut:
Contoh Perhitungan KNN Metode Euclidean Distance
Diketahui data berikut kemudian lakukan perhitungan Euclidean Distance:
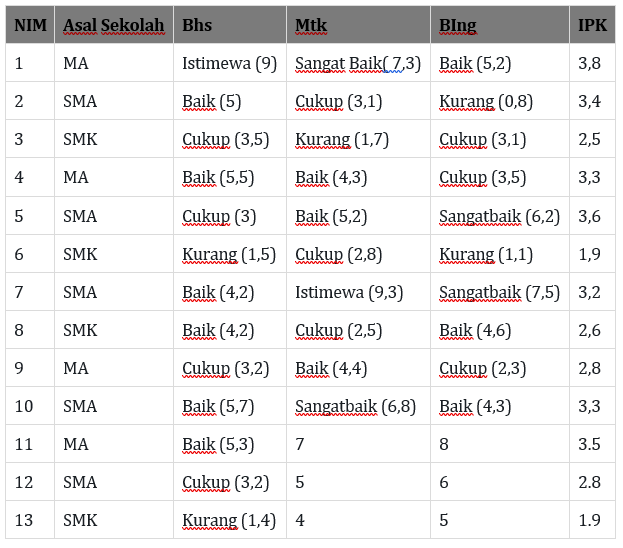
Keterangan: NIM 1-10 merupakan data lama, sedangkan NIM 11-13 merupakan data baru. ingat jika IPK < 3 = Mengecewakan, sedangkan
jika IPK >= 3 = Memuaskan
Kemudian hitung euclidean distance dari masing-masing data setiap nim terhadap masing-masing data baru (nim 11-13) dengan menggunakan rumus:

sedangkan X1 adalah data baru
serta tidak lupa untuk menentukan nilai terdekat (nilai euclidean terkecil) dengan cara dibuat urutan jarak dari terkecil hingga terbesar.
sehingga didapatkan hasil perhitungan untuk data baru pertama (NIM 11):
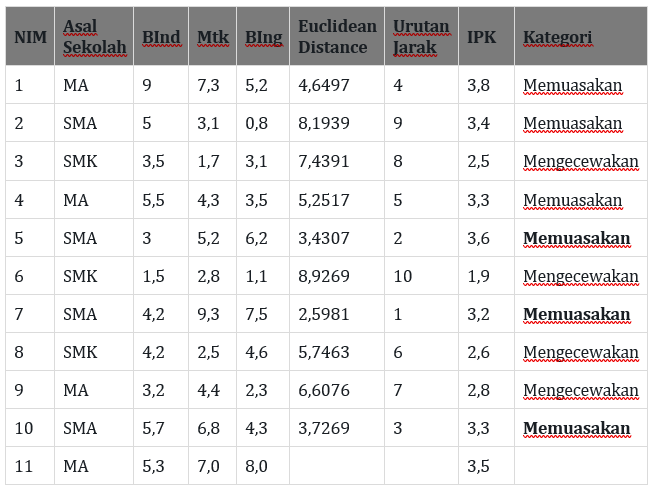
Dari hasil perhitungan diatas dengan menggunakan K=3, maka di dapatkan 3 nilai kategori yang semuanya menunjukkan kategori memuaskan. maka dapat disimpulkan bahwa nilai prediksi kategori IPK untuk data baru dengan nim 11 adalah “Memuaskan“.
hasil perhitungan untuk terhadap data baru kedua (NIM 12):

Dari hasil perhitungan diatas dengan menggunakan K=3, maka di dapatkan 3 nilai kategori yang menunjukkan kategori memuaskan, memuaskan, dan mengecewakan. maka dapat disimpulkan bahwa nilai prediksi kategori IPK untuk data baru dengan nim 12 adalah “Memuaskan“.
hasil perhitungan untuk terhadap data baru ketiga (NIM 13):
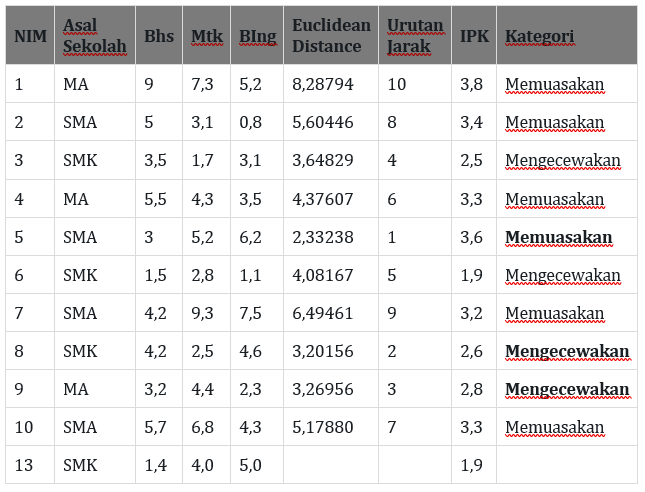
Dari hasil perhitungan diatas dengan menggunakan K=3, maka di dapatkan 3 nilai kategori yang menunjukkan kategori memuaskan, mengecewakan, dan mengecewakan. maka dapat disimpulkan bahwa nilai prediksi kategori IPK untuk data baru dengan nim 13 adalah “Mengecewakan“.
Setelah menguji 3 data uji, kita mendapatkan nilai prediksi dari setiap data uji yaitu:

selanjutkan kita akan mencari precission, recall, dan accuracy. dari perhitungan diatas.
| perlu di pahami : |
| TP = True Positive |
| TN =True Negative |
| FP = False Positive |
| FN = False Negative |
| Rumus | Perhitungan | Hasil | |
| Precission | TP/TP+FP | 1/(1+1) | 50% |
| Recall | TP/TP+FN | 1/(1+0) | 100% |
| Accuracy | TP+TN/TP+TN+FP+FN | (1+1)/(1+1+1+0) | 67% |
Contoh Perhitungan KNN Metode Manhattan
Diketahui data berikut kemudian lakukan perhitungan dengan metode Manhattan:

Keterangan: NIM 1-10 merupakan data lama, sedangkan NIM 11-13 merupakan data baru. ingat jika IPK < 3 = Mengecewakan, sedangkan
jika IPK >= 3 = Memuaskan
Kemudian hitung Manhattan dari masing-masing data setiap nim terhadap masing-masing data baru (nim 11-13) dengan menggunakan rumus yang hampir sama dengan rumus euclidean distance hanya saja tidak menggunakan akar.
dij = ∑Wk|xik – cjk|.
serta tidak lupa untuk menentukan 3 nilai terdekat (nilai Manhattan terkecil). sehingga didapatkan hasil perhitungan untuk data baru pertama (NIM 11):

Dari hasil perhitungan diatas dengan menggunakan K=3, maka di dapatkan 3 nilai kategori yang semuanya menunjukkan kategori memuaskan. maka dapat disimpulkan bahwa nilai prediksi kategori IPK untuk data baru dengan nim 11 adalah “memuaskan“.
hasil perhitungan untuk terhadap data baru kedua (NIM 12):

Dari hasil perhitungan diatas dengan menggunakan K=3, maka di dapatkan 3 nilai kategori yang menunjukkan kategori memuaskan, mengecewakan, mengecewakan. maka dapat disimpulkan bahwa nilai prediksi kategori IPK untuk data baru dengan nim 12 adalah “Mengecewakan“.
hasil perhitungan untuk terhadap data baru ketiga (NIM 13):

Dari hasil perhitungan diatas dengan menggunakan K=3, maka di dapatkan 3 nilai kategori yang semuanya menunjukkan kategori memuaskan, mengecewakan, mengecewakan. maka dapat disimpulkan bahwa nilai prediksi kategori IPK untuk data baru dengan nim 13 adalah “Mengecewakan“.
Setelah menguji 3 data uji, kita mendapatkan nilai prediksi dari setiap data uji yaitu:

Kemudian kita hitung nilai Presisi, Recall, Akurasi :
| Presisi | 1/(1+0)*100% | 100% |
| Recall | 1/(1+0)*100% | 100% |
| Akurasi | (1+2)/(1+2+0+0)*100% | 100% |
sumber: https://media.neliti.com/media/publications/155541-ID-penerapan-algoritma-k-nearest-neighbor-u.pdf
Categories
Preprocessing
Oleh: Achmad Ibrahim Humam – 17106050029
Data preprocessing adalah tahapan yang sangat penting dalam proses data mining. Data yang ingin diproses untuk data mining tidak selalu dalam bentuk yang ideal, maka perlu adanya data preprocessing untuk membuat data itu lebih ideal untuk diproses.
Di dalam data preprocessing, data disiapkan melalui beberapa tahap agar lebih berguna dan memiliki format yang lebih efisien. Langkah-langkah yang dilakukan dalam data preprocessing adalah kurang lebih sebagai berikut:
Sumber:
Jiawei Han, Micheline Chamber, and Jian Pei. “Data Mining Concepts and Techniques”
https://www.geeksforgeeks.org/data-preprocessing-in-data-mining/
