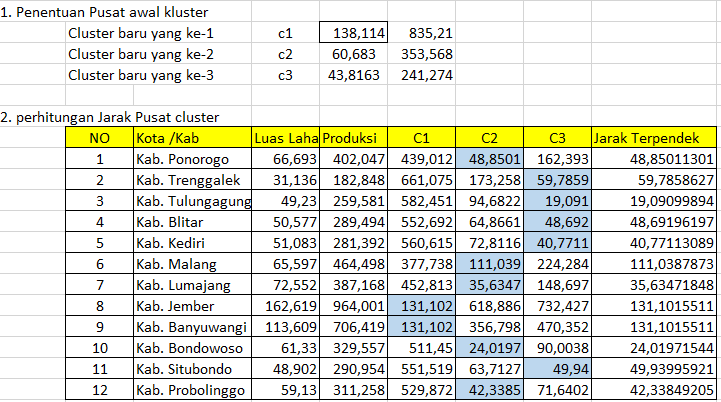
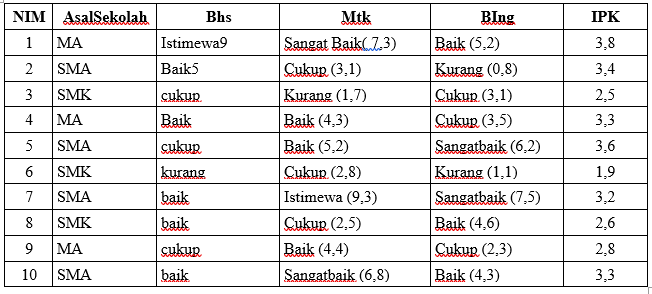
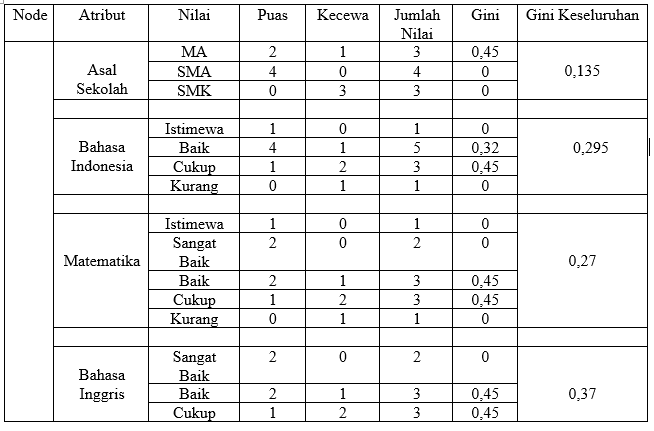
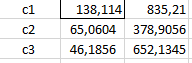17106050008 – Indri Dwi juanti
Asosiasi adalah metode yang menemukan suatu kombinasi item yang muncul bersamaan. Dalam dunia bisnis sering disebut dengan “Market Basket Analysis” atau analisis keranjang belanja . Biasanya menggunakan pola “jika(if) ” mewakili antecendent dan “maka(then)” mewakili consequence, bersamaan dengan pengukuran support (nilai penunjang) dan confidence (nilai kepastian) yang terasosiasi dalam aturan . Algoritma yang masuk kedalam Asosiasi adalah Algoritma Apriori, Fp Growth.
Penting tidaknya suatu aturan assosiatif dapat diketahui dengan dua parameter, support (nilai penunjang)
yaitu persentase kombinasi item tersebut dalam database dan confidence (nilai kepastian) yaitu kuatnya
hubungan antar item dalam aturan assosiatif.
Aturan assosiatif biasanya dinyatakan dalam bentuk :
{roti, mentega} -> {susu} (support = 40%, confidence = 50%)
Yang artinya : “50% dari transaksi di database yang memuat item roti dan mentega juga memuat item susu. Sedangkan 40% dari seluruh transaksi yang ada di database memuat ketiga item itu.” Dapat juga diartikan : “Seorang konsumen yang membeli roti dan mentega punya kemungkinan 50% untuk juga membeli susu. Aturan ini cukup signifikan karena mewakili 40% dari catatan transaksi selama ini.”
Analisis asosiasi didefinisikan suatu proses untuk menemukan semua aturan assosiatif yang memenuhi syarat minimum untuk support (minimum support) dan syarat minimum untuk confidence (minimum
confidence).
Metodologi dasar analisis asosiasi terbagi menjadi dua tahap :
a. Analisa pola frekuensi tinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database. Nilai
support sebuah item diperoleh dengan rumus berikut:

sedangkan nilai support dari 2 item diperoleh dari rumus berikut:

b. Pembentukan aturan assosiatif
Setelah semua pola frekuensi tinggi ditemukan, barulah dicari aturan assosiatif yang memenuhi syarat
minimum untuk confidence dengan menghitung confidence aturan assosiatif A ->B
Nilai confidence dari aturan A ->B diperoleh dari rumus berikut:

sumber :