Ahmad Mu’allal Hifni – 17106050034
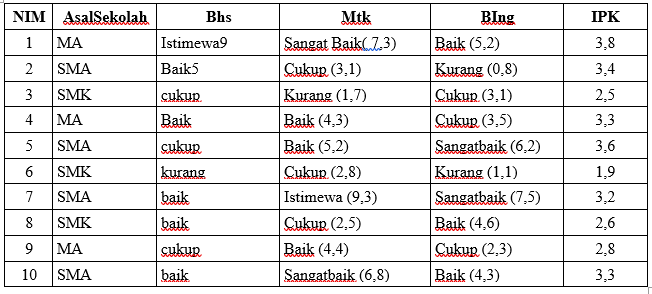
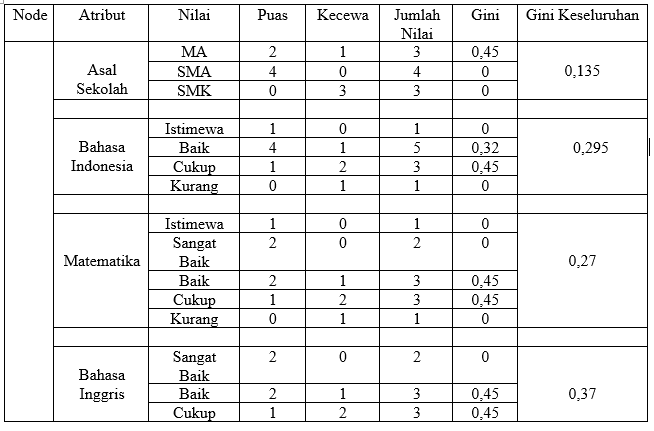
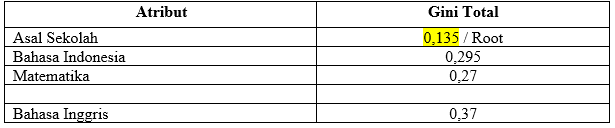
Klasterisasi (Clustering) merupakan pengelompokan sejumlah data atau objek ke dalam cluster (group) sehingga setiap dalam cluster tersebut akan berisi data yang semirip mungkin dan berbeda dengan objek dalam cluster yang lainnya.
Clustering yang paling efisien untuk menentukan cluster pada data dengan kepadatan yang berbeda adalah algoritma density based clustering. DBSCAN adalah salah satu contoh pelopor perkembangan teknik pengelompokan berdasarkan kepadatan atau yang biasa dikenal dengan sebutan density based clustering.
Perbedaan Klusterisasi dan Klasifikasi :
Dataset yang digunakan pada clustering tidak menampilkan class / target attribute, sedangkan dataset yang digunakan pada classification mutlak harus menampilkan class / target attribute.
Pengetahuan yang dihasilkan oleh metode clustering berupa cluster, sedangkan pengetahuan yang dihasilkan oleh metode classification berupa selain cluster (bisa Decision Tree, Ruleset, Weight pada BackPropagation, dan lain-lain).
Clustering dipakai ketika tidak diketahuinya bagaimana data harus dikelompokkan. Jumlah kelompok diasumsikan sendiri tanpa ditentukan terlebih dahulu. Keluaran pendekatan ini adalah data yang sudah dikelompokkan. Sedangkan classification, terdapat informasi mengenai bagaimana data tersebut dikelompokkan. Kemudian dilakukan training pada sistem dengan data yang sudah diberikan label (ke dalam kelompok manakah data tersebut dikelompokkan), selanjutnya sistem akan mengklasifikasikan data-data yang baru ke dalam kelompok yang ada. Tidak akan ada pertambahan kelompok.
Mind Map : Data Mining – Unsupervised – Klasterisasi
Sumber:
– Data Mining. Concepts and Techniques, 3rd Edition (The Morgan Kaufmann Series in Data Management Systems).
– Analisa Perbandingan Metode Hierarchical Clustering, K-means dan gabungan Keduanya dalam Cluster Data (Studi kasus : Problem Kerja Praktek Jurusan Teknik Industri ITS) oleh : Tahta Alfina, Budi Santosa, dan Ali Ridho Barakbah
– Implementasi Metode Clustering DBSCAN pada Proses Pengambilan Keputusan oleh : Ni Made Anindya Santika Devi,I Ketut Gede Darma Putra , I Made Sukarsa.