Unsupervised learning adalah salah satu tipe algoritma machine learning yang digunakan untuk menarik kesimpulan dari datasets yang terdiri dari input data labeled response. Metode unsupervised learning yang paling umum adalah analisa cluster, yang digunakan pada analisa data untuk mencari pola-pola tersembunyi atau pengelompokan dalam data. Salah satu algoritma yang digunakan metode unsupervised learning adalah K-Means algoritma.
Pendekatan unsupervised learning tidak menggunakan data latih atau data training untuk melakukan prediksi maupun klasifikasi. perbedaan Supervised Learning dengan Unsupervised Learning yaitu Supervised learning membutuhkan data training (harus dilatih terlebih dahulu) sedangkan unsupervised learning tidak membutuhkan data training (tidak perlu dilatih terlebih dahulu).
Misal dalam kasus pembagian kelompok mahasiswa pada suatu kelas yang akan dikelompokkan menjadi beberapa orang ini kedalam beberapa kelompok. Misalkan jumlah kelompok ada 4. Maka mahasiswa dikelompokkan menurut kesamaan ciri-ciri (atribut): berdasarkan indeks prestasi, jarak tempat tinggal atau gabungan keduanya. Dalam dua dimensi sumbu x merepresentasikan indeks prestasi, sumbu y merepresentasikan jarak tempat tinggal.
Teknik unsupervised : mahasiswa sebagai objek dari tugas kita, bisa dikempokkan dalam 4 kelompok menurut kedekatan IP dan jarak tempat tinggal. Pengelompokan ini, diasumsikan dalam satu kelompok, anggota-anggotanya harus memunyai kemiripan yang tinggi dibanding anggota dari kelompok lain.
Teknik supervised : output dari unsupervised dipakai sebagai guru dalam proses training dengan menggunakan teknik pengenalan pola , Dan dalam pemisahkan data training dan data testing (pelatih) maka diperlukan fungsi pemisah.
k-nearest neighbor (kNN) termasuk kelompok instance-based learning. Algoritma ini juga merupakan salah satu teknik lazy learning. kNN dilakukan dengan mencari kelompok k objek dalam data training yang paling dekat (mirip) dengan objek pada data baru atau data testing. Contoh kasus, misal diinginkan untuk mencari solusi terhadap masalah seorang pasien baru dengan menggunakan solusi dari pasien lama. Untuk mencari solusi dari pasien baru tersebut digunakan kedekatan dengan kasus pasien lama, solusi dari kasus lama yang memiliki kedekatan dengan kasus baru digunakan sebagai solusinya.
Pada Algoritma kNN terdapat beberapa metode perhitungan seperti Euclidean Distance dan Manhattan. untuk bisa memahami kedua metode perhitungan tersebut, maka perhatikan contoh berikut:
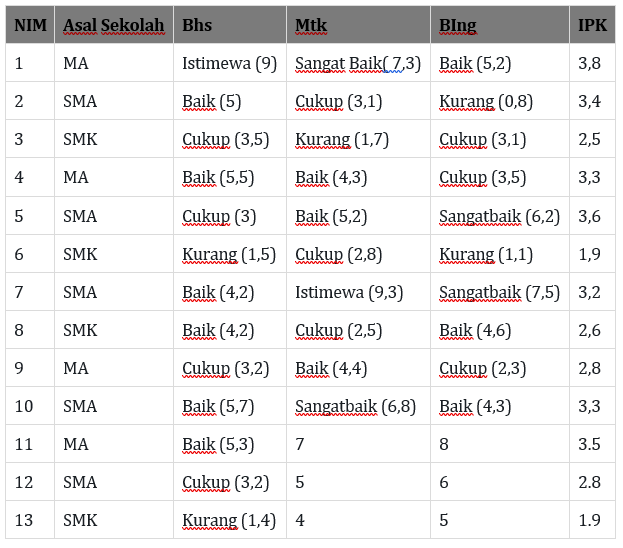
Contoh Perhitungan KNN Metode Euclidean Distance
Diketahui data berikut kemudian lakukan perhitungan Euclidean Distance:
Keterangan: NIM 1-10 merupakan data lama, sedangkan NIM 11-13 merupakan data baru. ingat jika IPK < 3 = Mengecewakan, sedangkan jika IPK >= 3 = Memuaskan
Kemudian hitung euclidean distance dari masing-masing data setiap nim terhadap masing-masing data baru (nim 11-13) dengan menggunakan rumus:
dimana X2 adalah data lama sedangkan X1 adalah data baru
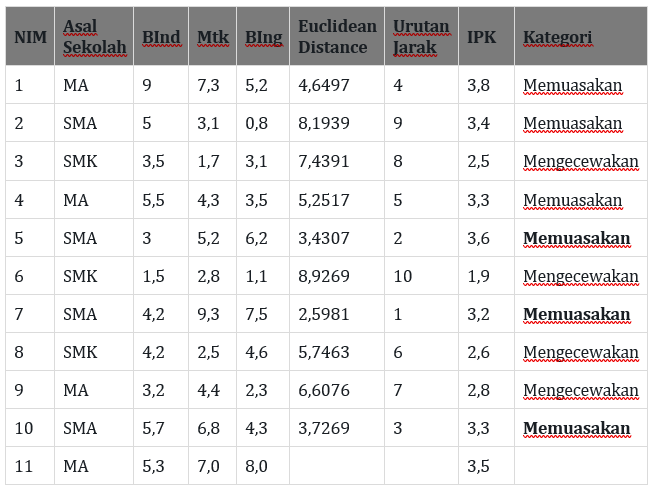
serta tidak lupa untuk menentukan nilai terdekat (nilai euclidean terkecil) dengan cara dibuat urutan jarak dari terkecil hingga terbesar. sehingga didapatkan hasil perhitungan untuk data baru pertama (NIM 11):
Dari hasil perhitungan diatas dengan menggunakan K=3, maka di dapatkan 3 nilai kategori yang semuanya menunjukkan kategori memuaskan. maka dapat disimpulkan bahwa nilai prediksi kategori IPK untuk data baru dengan nim 11 adalah “Memuaskan“.
hasil perhitungan untuk terhadap data baru kedua (NIM 12):
Dari hasil perhitungan diatas dengan menggunakan K=3, maka di dapatkan 3 nilai kategori yang menunjukkan kategori memuaskan, memuaskan, dan mengecewakan. maka dapat disimpulkan bahwa nilai prediksi kategori IPK untuk data baru dengan nim 12 adalah “Memuaskan“.
hasil perhitungan untuk terhadap data baru ketiga (NIM 13):
Dari hasil perhitungan diatas dengan menggunakan K=3, maka di dapatkan 3 nilai kategori yang menunjukkan kategori memuaskan, mengecewakan, dan mengecewakan. maka dapat disimpulkan bahwa nilai prediksi kategori IPK untuk data baru dengan nim 13 adalah “Mengecewakan“.
Setelah menguji 3 data uji, kita mendapatkan nilai prediksi dari setiap data uji yaitu:
selanjutkan kita akan mencari precission, recall, dan accuracy. dari perhitungan diatas.
perlu di pahami :
TP = True Positive
TN =True Negative
FP = False Positive
FN = False Negative
Rumus
Perhitungan
Hasil
Precission
TP/TP+FP
1/(1+1)
50%
Recall
TP/TP+FN
1/(1+0)
100%
Accuracy
TP+TN/TP+TN+FP+FN
(1+1)/(1+1+1+0)
67%
Contoh Perhitungan KNN Metode Manhattan
Diketahui data berikut kemudian lakukan perhitungan dengan metode Manhattan:
Keterangan: NIM 1-10 merupakan data lama, sedangkan NIM 11-13 merupakan data baru. ingat jika IPK < 3 = Mengecewakan, sedangkan jika IPK >= 3 = Memuaskan
Kemudian hitung Manhattan dari masing-masing data setiap nim terhadap masing-masing data baru (nim 11-13) dengan menggunakan rumus yang hampir sama dengan rumus euclidean distance hanya saja tidak menggunakan akar.
dij = ∑Wk|xik – cjk|.
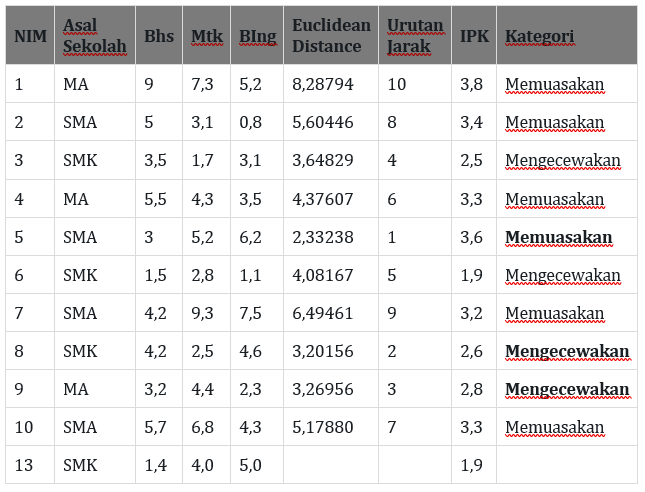
serta tidak lupa untuk menentukan 3 nilai terdekat (nilai Manhattan terkecil). sehingga didapatkan hasil perhitungan untuk data baru pertama (NIM 11):
Dari hasil perhitungan diatas dengan menggunakan K=3, maka di dapatkan 3 nilai kategori yang semuanya menunjukkan kategori memuaskan. maka dapat disimpulkan bahwa nilai prediksi kategori IPK untuk data baru dengan nim 11 adalah “memuaskan“.
hasil perhitungan untuk terhadap data baru kedua (NIM 12):
Dari hasil perhitungan diatas dengan menggunakan K=3, maka di dapatkan 3 nilai kategori yang menunjukkan kategori memuaskan, mengecewakan, mengecewakan. maka dapat disimpulkan bahwa nilai prediksi kategori IPK untuk data baru dengan nim 12 adalah “Mengecewakan“.
hasil perhitungan untuk terhadap data baru ketiga (NIM 13):
Dari hasil perhitungan diatas dengan menggunakan K=3, maka di dapatkan 3 nilai kategori yang semuanya menunjukkan kategori memuaskan, mengecewakan, mengecewakan. maka dapat disimpulkan bahwa nilai prediksi kategori IPK untuk data baru dengan nim 13 adalah “Mengecewakan“.
Setelah menguji 3 data uji, kita mendapatkan nilai prediksi dari setiap data uji yaitu:
Kemudian kita hitung nilai Presisi, Recall, Akurasi :